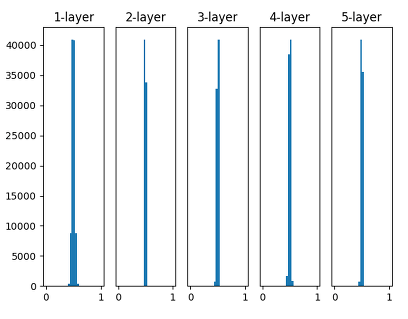
When using Weights in Gaussian Distribution which has mean 0 and variance 1, Output tends to be 0 or 1. Sigmoid’s Gradient Vanishing near 0 and 1 is the reason. We can figure it out with not only Changing Activation Fuction but also Initializing Weights.
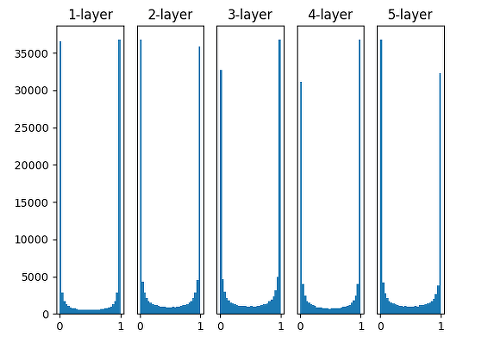
Using Gaussian Distribution which has smaller Variance
Using Weights in Gaussian Distribution which has variance 0.01 makes much more meaningful result.
Xavier Initialization
Output from layers should have Gaussian Distribution to get a stable train. Xavier Initialization is scaling weights by Square root of input data number(\( 1/\sqrt{n} \)).
w = np.random.randn(n_input,n_output)/sqrt(n_input)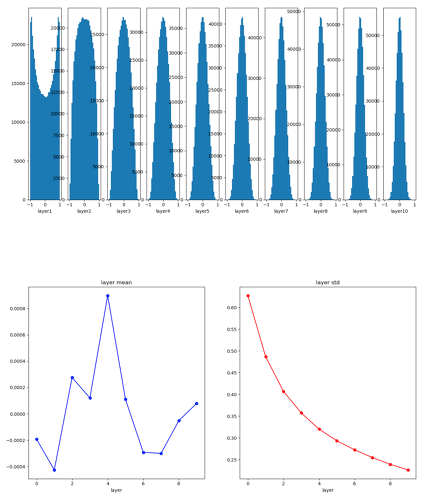
Xavier makes much better result for Sigmoid. But, it is bad idea using Xavier for ReLU.
He Initialization
He Initialization is made for ReLU. It’s very similar with Xavier. But, it scales weights by Square root of half input data number(\( 1/\sqrt{n/2} \)).
w = np.random.randn(n_input,n_output)/sqrt(n_input/2)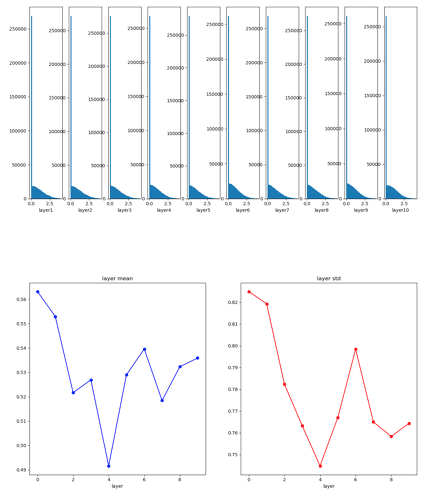
Conclusion
For Sigmoid or Tanh, Use Xavier Initialization! For ReLU, Use He Initialization!
Reference
https://gomguard.tistory.com/184